Acknowledgments
This project is done by Hani Safadi, as a class requirement of the Pattern Recognition
course taught by Prof. Godfried Toussaint at McGill University, Fall 2006. The main
reference is a paper titled Geometrical Tools in Classification by J.P. Rasson and V. Granville, published in Computational
Statistics and Data Analysis 23 (1996).
I would like to thank my instructor Prof. Godfried Toussaint for this interesting course. I would my also to thank my TA
Erin McLeish for helping me and giving feedback during the stages of this
project. Finally, I would like to thank Prof. Luc Devroye who explained me the Poisson process generation techniques.
Introduction
"Classification is a fundamental class of techniques that has
applications in a huge number of areas, such as pattern recognition, machine
learning, and robotics.
It is used to partition a "universe" of all possible objects,
each described as a bunch of data into a set of classes. It is mainly
characterized by its decision rule. This rule determines, for a given object,
which class it belongs to.
There are two fundamental classes of decision rules: parametric and
non-parametric rules.
Parametric decision rules make the membership classification based on the
knowledge of the priori probabilities of occurrence of objects belonging to
some class Ci. This is captured by the probability
density function, p(X|Ci),
which characterize how probable the measurement X is should the membership
class be Ci.
Very often, however, it is difficult to describe these probability density
functions a priori, and often they are just unknown.
In such cases, non-parametric decision rules are attractive, because they
do not require such a priori knowledge. Instead these rules rely directly on
the training set of objects. For this set, the class membership is known
precisely for each object in this set. This is a priori knowledge, too, but
much less difficult to acquire (For instance, it could be provided by a
human.) Therefore, this is also called supervised learning. The idea is that
a "teacher" feeds a number of example objects to the "student"
and provides the correct answer for each of them. After the learning phase,
the student tries to determine the correct answer for unseen objects based on
the examples it has seen so far.
Usually, objects are represented by a set of features, each of which can
usually be represented by a real number. Thus, objects can be represented as
points in the so-called feature space, and classes are subsets of this space.
Since we work with points, we can usually define a measure of distance
between points (which might be more or less well adapted to the objects).
A very simple, non-parametric decision rule is the nearest-neighbour classifier. As it name suggests, it is based on
the distance measure, and it assigns an unknown object to the same class as
the nearest object from the (known) training set." [2]
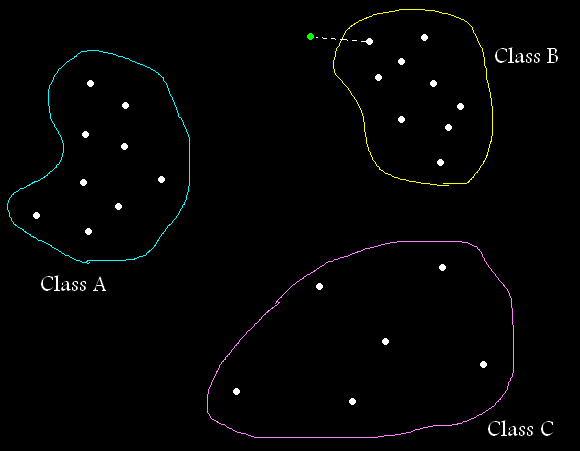
Classification is assining lables to new points
Other variations to nearest-neighbor exist, but they all share the same
property (and problems): Give the unknown object the class of the objects
near to it.
The problems with non-parametric methods is that they require more space
to store the model (which is in nearest-neighbor the whole training set) and
more time to classify new objects since we should measure its distance to
each item in the training set. It also create many
local approximations, which could be problematic with a noisy training set.
[3]
In this project we will describe a new methods used to alleviate the
problems of non-parametric methods, namely the large training set
requirements and the locality problem.
Those methods rely on geometry as a tool. The construct that will be used is
the "Convex Hull".
|
